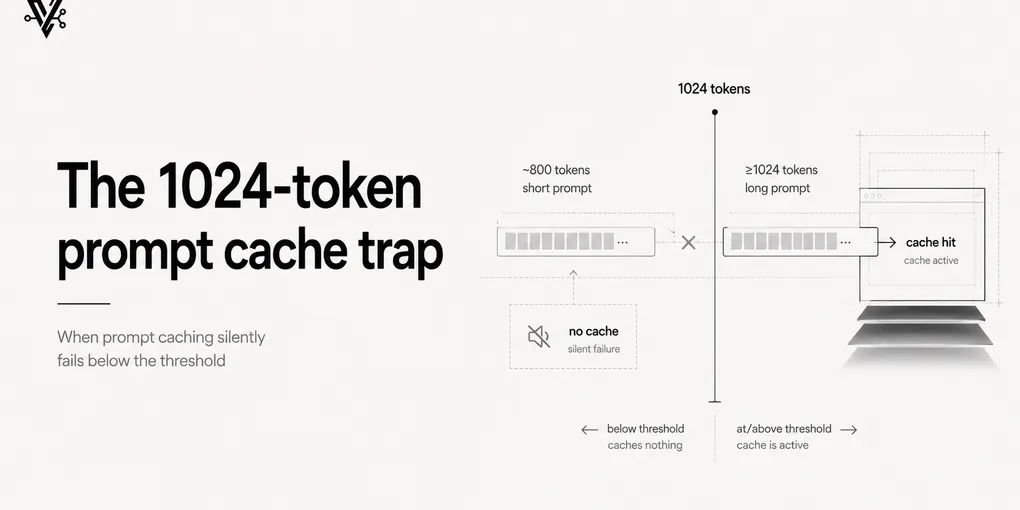
The 1024-token prompt cache trap
If you’re using Anthropic’s prompt caching to cut costs on a long-running agent, there’s one number you have to know: 1024 tokens.
That’s the minimum length your cache_control block has to clear before
Anthropic actually caches anything. Below it, the API accepts your request,
returns a perfectly normal response, charges you full price — and silently
caches nothing. No error. No warning. Just a quietly broken optimization.
This bit us on Forge, MagmaLabs’ Virtual Employee Platform, when we introduced a new Virtual Employee with a tight system prompt. The token count came in around 800. We watched the cost dashboard and saw nothing improve. No 90% discount on cache hits. The agent was running. The cache_control headers were there. But every request was a fresh prompt to Anthropic, paid in full.
How to know if it’s actually working
There’s exactly one reliable signal: the cache_creation_input_tokens and
cache_read_input_tokens fields in the response’s usage block.
response = anthropic.messages.create(
model: "claude-sonnet-4-5",
system: [
{ type: "text", text: SYSTEM_PROMPT,
cache_control: { type: "ephemeral" } }
],
messages: [...]
)
usage = response.usage
puts "cache_creation: #{usage.cache_creation_input_tokens}" # should be > 0 on first call
puts "cache_read: #{usage.cache_read_input_tokens}" # should be > 0 on subsequent calls
puts "input: #{usage.input_tokens}" # uncached portionIf cache_creation_input_tokens is 0 on the very first call — your
prompt is below the minimum. Caching is not happening. You’re paying
full price.
The fix isn’t padding
The instinct is to pad the system prompt with filler to clear 1024 tokens. Don’t. You’re paying for those filler tokens on every request and you’re diluting the actual signal the model needs.
Better options:
-
Move more into the cached block. If you have a tool definitions block, examples, or a long persona description that you were keeping in user messages — move it into the system prompt under
cache_control. These are content the agent legitimately needs, and they push you over the threshold without inflating your bill per request. -
Cache the tool list. Anthropic now lets you put
cache_controlon the tools array. If you have a few JSON-Schema’d tools, they often account for hundreds of tokens by themselves. -
Accept that caching isn’t the right optimization here. If your actual prompt is short, prompt caching wasn’t going to save you that much anyway. Spend the optimization energy on batch API, smaller models for sub-tasks, or just letting it be.
What I’d tell past-me
Don’t pitch prompt caching as a cost fix without verifying
cache_creation_input_tokens > 0 on a real call. The marketing math
(“90% off cached tokens!”) is real, but only above the 1024-token line.
Below it, you’ve added complexity for no benefit.
The lesson generalizes: when a provider’s optimization has a silent failure mode, build the verification into your own observability before you ship. Don’t trust headers — trust counters.